Webhooks are a powerful way to enable real-time communication between systems, but they can become overwhelming as traffic spikes or event volumes increase. The solution? Asynchronous processing. By separating webhook receipt from processing, you can handle high traffic efficiently without timeouts, server crashes, or retry storms.
This approach ensures your webhook system remains reliable, even during high-traffic events like Black Friday or major sales. Start by implementing a durable queue and lightweight ingestion layer to prevent disruptions and improve processing efficiency. For step-by-step guidance on setting up these systems, explore our AI receptionist tutorials.
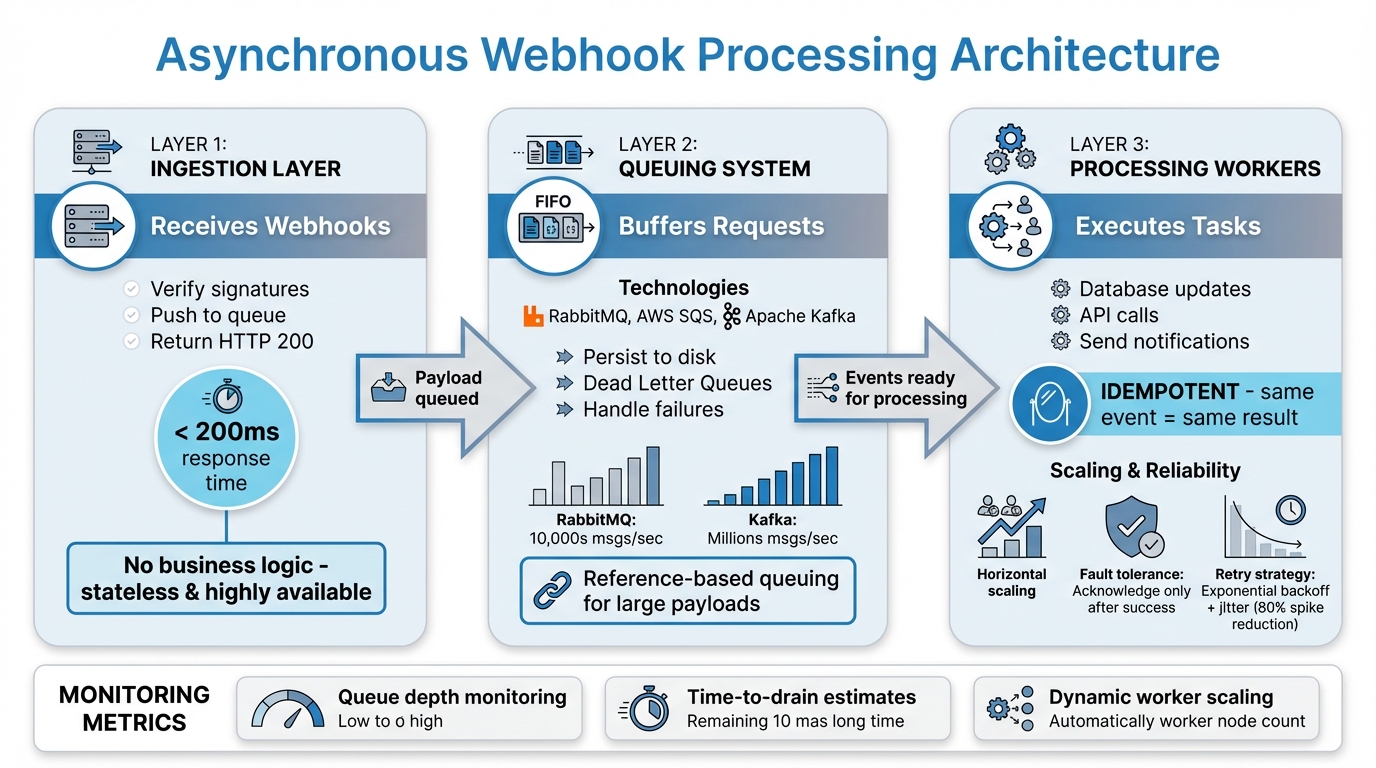
Three-Layer Architecture for Asynchronous Webhook Processing
Creating a webhook system that can handle scale effectively requires three interconnected layers. Together, these layers turn synchronous webhook receipt into a streamlined background processing pipeline. Each layer addresses unique challenges, ensuring the system remains efficient and avoids bottlenecks.
The ingestion layer is where everything begins. Its main job is to capture incoming webhook requests, verify their signatures, and quickly push the payload into a queue. This ensures the system can send an HTTP 200 response back to the provider within 200ms, meeting their expectations. Here's a key piece of advice from Art Light, CTO:
"Never do business logic in the webhook handler"
If you add business logic at this stage, you risk timeouts and triggering unnecessary retries from the provider. To avoid this, the ingestion layer should remain stateless and highly available. If it slows down or becomes unavailable, you could lose events or have providers mark your webhooks as failed.
Once the payload is captured, the queuing system steps in to manage the next stage.
The queuing system acts as a buffer, ensuring incoming webhooks are safely stored and ready for processing. Tools like RabbitMQ or AWS SQS are commonly used for this purpose. These message brokers persist messages to disk to prevent data loss and handle failures using Dead Letter Queues. This separation allows the system to acknowledge webhook events quickly, even during traffic spikes.
For example, RabbitMQ and ActiveMQ can process tens of thousands of messages per second. Meanwhile, high-throughput systems like Apache Kafka can handle millions of messages using topic partitions. If you're dealing with large payloads in high-volume systems, you can optimize further by using reference-based queuing - store the payload in a service like AWS S3 and queue only a reference to it. This approach can cut costs and boost performance.
With events securely buffered, the processing workers take over to execute the necessary tasks.
Processing workers are the engine of the system, handling the actual business logic. They process events from the queue at a steady pace, performing actions like updating databases, calling external APIs, or sending notifications via post-call webhooks. Since these workers operate asynchronously, you can scale them horizontally by adding more instances to handle increased loads without overloading the system.
To ensure reliability, workers must be idempotent - processing the same event multiple times should always produce the same result. As Phil Leggetter from Hookdeck puts it:
"An operation is said to be idempotent if performing it multiple times produces the same result as performing it once"
This is critical because webhook providers guarantee "at-least-once" delivery. To prevent data corruption, you can use unique event IDs or a "fetch-before-process" strategy.
For fault tolerance, workers should only acknowledge a message (removing it from the queue) after successfully completing the task. If something goes wrong, the message gets re-queued or moved to a retry queue, often with exponential backoff. Adding jitter (random intervals) to retries can reduce synchronized retry spikes by over 80% in real-world systems. By monitoring metrics like queue depth and time-to-drain estimates, you can adjust the worker pool dynamically during peak periods to maintain smooth operations.
Asynchronous webhook processing boils down to three key steps: ingest, queue, and process. Here's how to make it work effectively.
The ingestion endpoint should be as lightweight as possible. Its primary job? Receive the webhook, verify the signature, and push the payload into a queue. Once that's done, it should return an HTTP 200 response right away. As Hookdeck explains:
"Your server should perform the bare minimum amount of work upon receiving a webhook. We call this asynchronous processing."
Start by creating a POST endpoint. Use the raw request body to verify the HMAC-SHA256 signature - this avoids errors caused by JSON parsing. Once verified, immediately push the payload into a queue and respond within 200ms to prevent timeouts from the webhook provider.
For infrastructure, serverless platforms like AWS Lambda or Google Cloud Functions are excellent choices. They scale automatically to handle spikes in traffic. If the payload is too large, consider storing it in AWS S3 and queuing a reference to the file instead.
The key here is speed: ingest and acknowledge the webhook quickly, then buffer the payload securely in a durable queue.
A reliable queue is essential for handling failures and ensuring smooth processing. Use a message broker like RabbitMQ or AWS SQS, and configure it for durability, persistence, and explicit acknowledgments. To prevent issues caused by problematic messages, set up Dead Letter Queues (DLQs). These isolate messages that fail repeatedly, keeping your pipeline running smoothly .
Explicit acknowledgments are critical. Workers should only remove messages from the queue after successfully completing their tasks. If a worker crashes mid-task, the message stays in the queue, ready for another worker to pick up . For high volumes, implement rate limiting - such as 60 events per minute - to avoid overwhelming downstream systems .
In multi-tenant systems, per-tenant queues or circuit breakers are helpful. They ensure that one customer's failing endpoint doesn't disrupt the entire system. Instead of just monitoring queue depth, track the "estimated time to drain" metric. This gives you a clearer picture of whether your processing rate is keeping up with webhook ingestion.
Once your queue is reliable, you're ready to scale up the workers that handle the actual business logic.
Processing workers are where the real work happens - whether it's updating databases, calling APIs, or sending notifications. To handle varying workloads, scale these workers dynamically based on metrics like queue depth or processing time.
The most important requirement for workers is idempotency. As Art Light, CTO, warns:
"If your system is not idempotent, retries are data corruption."
To ensure idempotency, generate unique keys (such as a hash of the provider ID and event type) and enforce them with unique database constraints. Use a fetch-before-process approach with the event ID to ensure you're working with the latest data.
Workers should only acknowledge a message after the processing result or side effect has been successfully saved . For retries, use a multi-tier strategy: immediate retries for minor network issues, exponential backoff with jitter for longer outages, and a long-term retry queue (3-7 days) for extended downtime. To reduce latency when making downstream calls, use connection pooling with keep-alive.
After setting up a dependable asynchronous webhook system, you can expand its functionality by linking it to external platforms. These platforms act as destinations, receiving the processed webhook data once it has been ingested and queued.

Zapier integrates with over 9,000 apps, making it an excellent tool for automating workflows powered by webhooks. To connect your asynchronous system with Zapier, direct queued webhook data to Zapier's HTTP endpoint. This approach ensures your ingestion layer remains efficient while managing high-volume bursts by buffering data before delivery.
One key factor to manage here is rate limiting. Platforms like Zapier enforce API rate limits, and exceeding these limits can result in 429 Too Many Requests errors. To avoid this, adjust your worker pool to align with the API's rate limits. For instance, if a CRM system allows 100 requests per second, configure your workers to stay within that limit to prevent overloading the destination.
Additionally, you'll need to set up data transformation rules to adapt webhook payloads into formats that are compatible with the target platform.
Post-call webhooks are another way to streamline workflow automation, sending call data to external systems for further processing.
My AI Front Desk utilizes post-call webhooks to share data - such as transcriptions, outcomes, and caller details - with external platforms after a call ends. Once the webhook is acknowledged, the call data can be queued (e.g., using AWS SQS), helping to protect downstream APIs from traffic surges during peak call times. Processing workers can then forward this data to CRM systems, analytics tools, or automation platforms like Zapier.
With My AI Front Desk's built-in Zapier integration, connecting call data to thousands of apps becomes effortless, eliminating the need for custom coding. If your workflow requires the most current resource state, you can use the "fetch before process" pattern. In this setup, treat the webhook as a notification and retrieve the latest data from the provider's API before processing to ensure accuracy and consistency.
Small mistakes can lead to duplicate processing, data loss, or system overload. Here's a breakdown of key practices to follow and pitfalls to avoid.
Most webhook providers use "at-least-once" delivery, which means you should expect duplicates or events arriving out of order. Without proper safeguards, this can result in issues like processing the same payment twice or sending duplicate emails - both of which can corrupt your data.
"If your system is not idempotent, retries are data corruption."
– Art Light, CTO
To avoid this, generate a unique idempotency key by hashing critical identifiers like the provider name, event type, and external object ID. Store this key in your database or a tool like Redis with a unique constraint. When a webhook arrives, check if the key already exists. If it does, skip processing. If the event is currently being handled, return a 409 Conflict response so the provider retries later.
For systems where only the most recent state matters, consider SQL upserts with timestamp checks. Add a WHERE clause to your ON CONFLICT logic to ensure only newer data overwrites existing records. Another approach, known as "Fetch Before Process", treats the webhook as a notification. Instead of processing the payload directly, pull the latest resource state from the provider’s API. This guarantees you're working with up-to-date information but can increase API usage and risk hitting rate limits (e.g., Stripe’s 100 read requests per second limit).
Once idempotency is in place, focus on keeping your webhook handling lightweight to prevent timeouts.
Webhook endpoints should be optimized for speed. They need to respond within 1–2 seconds to avoid triggering retries from the provider. The endpoint should perform only essential tasks: verifying the signature, saving the raw payload to a queue, and returning a 200 OK response. Doing heavy processing inline risks timeouts, dropped connections, and retry storms during traffic spikes.
To prevent these issues, decouple ingestion from processing. Keep the endpoint simple and let background workers handle the heavy lifting.
Once your architecture is in place, real-time monitoring becomes crucial to ensure scalability. Track metrics like queue depth (number of pending events) and max age (age of the oldest event). Combining these into an "estimated time to drain" metric gives a clear view of how well your system is keeping up. Use this data to scale dynamically. For example, in Kubernetes, a Horizontal Pod Autoscaler (HPA) can adjust worker pods based on queue depth. On serverless platforms like AWS Lambda or Google Cloud Functions, automatic scaling is often built-in.
To further protect your system, implement circuit breakers for individual tenants. This prevents one slow or failing endpoint from monopolizing resources. Set up alerts for your Dead Letter Queue (DLQ) to catch unprocessed events. Finally, add jitter to retry intervals - introducing randomness to retry timing can reduce traffic spikes by over 80%.
Asynchronous processing has redefined how webhook systems handle scalability challenges. By separating the ingestion of events from their processing, this method ensures your endpoint queues events for later execution. This approach shields your system from timeout errors, server crashes during traffic surges, and data loss when downstream services experience downtime.
The results speak for themselves. During Black Friday 2024, Hookdeck's queue-first architecture allowed customers to handle 10 times their usual traffic without experiencing a single timeout or service disruption. As Phil Leggetter from Hookdeck aptly puts it:
"Webhooks are simple until they're not. Once you grow beyond a certain point, the cost of poor webhook handling shows up in developer time, incident response, and customer experience".
At its core, asynchronous processing ensures webhook systems remain reliable and scalable. The three-layer architecture - comprising ingestion, queuing, and processing - allows each component to scale independently. Workers can scale horizontally to match queue depth, while the ingestion layer stays lightweight. When combined with techniques like idempotency checks, exponential backoff with jitter, and circuit breakers, this approach effectively manages the complexities of distributed systems. As Gareth Wilson from Hookdeck explains:
"Exactly-once delivery is a myth... the industry standard is at-least-once delivery combined with idempotent processing on the receiving end".
Armed with these principles, you are well-equipped to implement robust webhook solutions.
Take these insights and strengthen your webhook system. Begin by integrating a durable message queue between your webhook endpoint and processing logic. Tools like AWS SQS or RabbitMQ are excellent starting points. Set up a Dead Letter Queue to capture failed events, and monitor metrics like queue depth and maximum age to spot backpressure before it escalates into larger issues.
This foundation sets the stage for seamless automation. Platforms like Zapier, which connects with over 9,000 apps, make it easy to automate workflows. If you're leveraging an AI-driven phone system, My AI Front Desk offers post-call webhooks that send call data to external systems. This enables you to trigger actions based on conversation content, manage multiple calls simultaneously, and integrate directly with your CRM. With these tools, you can build workflows that respond to customer interactions in real time, streamlining operations and enhancing efficiency.
Asynchronous processing plays a crucial role in avoiding webhook timeouts by splitting the receipt of a webhook from the tasks that follow. When a webhook is received, the system can quickly send back an acknowledgment to the sender. This immediate response ensures that no timeout issues arise, while the actual processing is handed off to a background task.
This method becomes particularly handy during periods of heavy traffic. By reducing delays and maintaining responsiveness, it helps the system handle webhooks efficiently, ensuring it remains scalable and dependable.
Message brokers like RabbitMQ play a key role in scaling webhook systems by enabling asynchronous processing. Acting as intermediaries, they queue incoming webhook events, allowing delivery and processing to work independently of each other. This separation helps manage high traffic efficiently, handle retries, and minimize the chances of failures.
With a message broker in place, webhook systems can process events at a manageable pace, even during sudden traffic surges. This ensures smoother operations, better reliability, and the ability to handle heavy loads without breaking a sweat.
Idempotency plays a key role in ensuring that processing the same webhook request multiple times doesn’t create unexpected side effects or cause data inconsistencies. This becomes especially critical when dealing with large volumes of webhook traffic, where duplicate requests might happen due to retries or network glitches.
By using idempotency, you can guarantee that your system handles each event reliably and accurately, even when retries occur. This approach helps protect data integrity and supports better scalability.
Start your free trial for My AI Front Desk today, it takes minutes to setup!








